在开始今天的正文之前,我们先了解一下 Linux 系统的权限设计。
在 Linux 系统中,为了保证文件的安全,对文件所有者、同组用户、其他用户的访问权限进行了分别管理。其中,文件所有者,即建立文件或目录的用户;同组用户,是所属组群中的所有用户;其他用户,指的是既不是文件所有者,也不是同组用户的其他用户。每个文件和目录都具有读取权限、写入权限和执行权限,这三个权限之间相互独立。
| 权限 | 文件 | 目录 |
|---|---|---|
| 读取权限 | 可以查看文件内容 | 可以列出目录的内容 |
| 写入权限 | 可以修改文件的内容 | 可以在目录中创建、删除文件 |
| 执行权限 | 可以执行文件 | 可以进入文件 |
在 Linux 系统中,每个文件的访问权限可以用 9 个字母表示,每 3 个字母表示一类用户权限,分别代表文件创建者、同组用户、其他用户。其中,r 表示读取权限,w 表示写入权限,x 表示执行权限。通过功能模式修改文件权限,有三个部分组成,包括对象、操作和权限。
| 对象 | 操作 | 权限 |
|---|---|---|
u 文件所有者 | + 增加权限 | r 读取权限 |
g 同组其他用户 | - 删除权限 | w 写入权限 |
o 其他用户 | = 重新分配权限 | x 执行权限 |
a 所有用户(默认) |
假设需要增加同组用户写入权限,下面来看一个例子。
chmod g+w /var/log/nginx/access.log此外,每一类用户的访问也可以通过数字的方式进行表示。
| 字母表示形式 | 数字表示形式 | 权限含义 |
|---|---|---|
--- | 0 | 无任何权限 |
--x | 1 | 可执行权限 |
-w- | 2 | 可写入权限 |
-wx | 3 | 可写入+可执行权限 |
r-- | 4 | 可读取权限 |
r-x | 5 | 可读取+可执行权限 |
rw- | 6 | 可读取+可写入权限 |
rwx | 7 | 可读取+可写入+可执行权限 |
那么,通过数字模式就可以对常见的 Linux 文件权限操作进行归纳。
| 数字形式 | 字母形式 | 权限含义 |
|---|---|---|
444 | r--r--r-- | 创建者可读,同组用户可读,其他用户可读 |
600 | rw------- | 创建者可读可写,同组用户无权限,其他用户无权限 |
644 | rw-r--r-- | 创建者可读可写,同组用户可读,其他用户可读 |
666 | rw-rw-rw- | 创建者可读可写,同组用户可读可写,其他用户可读可写 |
700 | rwx------ | 创建者可读可写可执行,同组用户无权限,其他用户无权限 |
744 | rwxr--r-- | 创建者可读可写可执行,同组用户可读,其他用户可读 |
755 | rwxr-xr-x | 创建者可读可写可执行,同组用户可读可执行,其他用户可读可执行 |
777 | rwxrwxrwx | 创建者、同组用户及其他用户均拥有全部权限 |
假设需要设置创建者可读可写可执行、同组用户可读、其他用户可读,我们可以这样写:
chmod 755 /var/log/nginx/access.log事实上,Linux 的文件访问权限就是非常经典的位运算使用场景。无独有偶,我们再来看下 Java 中的 java.lang.reflect.Modifier。其中, Modifier 类采用 16 进制定义了静态常量。
public static final int PUBLIC = 0x00000001;
public static final int PRIVATE = 0x00000002;
public static final int PROTECTED = 0x00000004;
public static final int STATIC = 0x00000008;
public static final int FINAL = 0x00000010;
public static final int SYNCHRONIZED = 0x00000020;
public static final int VOLATILE = 0x00000040;
public static final int TRANSIENT = 0x00000080;
public static final int NATIVE = 0x00000100;
public static final int INTERFACE = 0x00000200;
public static final int ABSTRACT = 0x00000400;
public static final int STRICT = 0x00000800;
...紧接着,Modifier 类提供了很多静态方法,例如 isPublic() 方法的返回值 & PUBLIC 对应的 16 进制值,如果非 0,则说明含有 public 修饰符。
public static boolean isPublic(int mod) {
return (mod & PUBLIC) != 0;
}这里有一个重要的知识点,采用 & 运算,两位同时为 1,结果才为 1,否则为 0。即:
0 & 0 = 00 & 1 = 01 & 0 = 01 & 1 = 1
例如:3 & 1 即 0000 0011 & 0000 0001 = 00000001,值为 1。
0000 0011
& 0000 0001
= 0000 0001与此同时,Modifier 类还采用 | 运算,确保参加运算的两个对象只要有一个为 1,其值为 1。即:
0 | 0 = 00 | 1 = 11 | 0 = 11 | 1 = 1
例如 Modifier.PUBLIC | Modifier.PROTECTED | Modifier.PRIVATE | Modifier.ABSTRACT | Modifier.STATIC | Modifier.FINAL | Modifier.STRICT 的结果是 3103,即 110000011111。
private static final int CLASS_MODIFIERS =
Modifier.PUBLIC | Modifier.PROTECTED | Modifier.PRIVATE |
Modifier.ABSTRACT | Modifier.STATIC | Modifier.FINAL |
Modifier.STRICT;
0000 0000 0000 0001
| 0000 0000 0000 0010
| 0000 0000 0000 0100
| 0000 0000 0000 1000
| 0000 0000 0001 0000
| 0000 0100 0000 0000
| 0000 1000 0000 0000
= 0000 1100 0001 1111言归正传,我们站在前辈们的肩上,通过位运算设计优雅的多选标识,例如通过位运算实现权限控制或多状态管理,它的好处在于易扩展,避免数据库设计过程中字段膨胀,减少磁盘存储空间。
假设,我们现在有一个有一个业务需求:在任务中添加一个通知方式,可选项包括 IM 消息、系统提醒、邮箱、短信。选择 IM 消息后,支持 IM 即时发送;选择系统提醒后,支持站内信推送;选择选择邮箱后,该任务后续相关提醒内容,可通过发送邮件至相关人邮箱中进行通知;选择短信后,该任务后续相关提醒内容,可通过发送短信至相关人进行通知。

我们在设计数据库库表时,通常情况下,将多个标识字段合并成一个字段,并把这个字段改成字符串型方式保存,例如,存在 1 时表示支持 IM,2 时表示支持系统消息,3 表示支持邮箱,4 表示支持短信。此时,如果同时都满足,它的存储形式就是以逗号分隔的字符串:“1,2,3,4”。这样设计的好处在于,不仅消除相同字段的冗余,而且当增加新的渠道类别时,不需增加新的字段。
IM(1, "IM消息"),
SYSTEM(2, "系统提醒"),
MAIL(3, "邮箱"),
SMS(4, "短信");但在数据查询时,我们需要对字符串进行分隔。并且字符串类型的字段在查询效率和存储空间上不如整型字段。因此,我们可以用“位”来解决这个问题。我们采取不同的位来分别表示不同类别的标识字段。
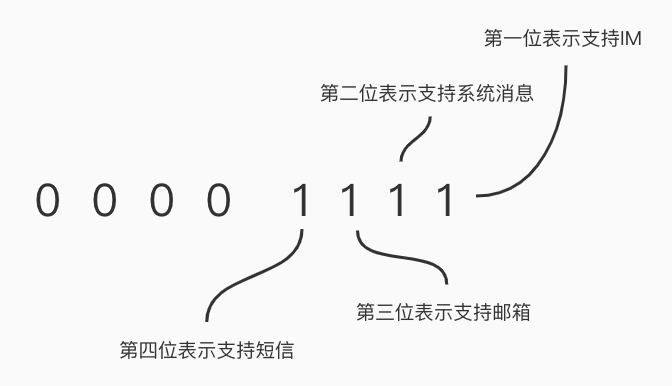
因此,当某个任务:
- 支持 IM 时,则保存 1(0000 0001)
- 支持系统消息时,则保存 2(0000 0010)
- 支持邮箱时,则保存 4(0000 0100)
- 支持短信时,则保存 8(0000 1000)
- 四种都支持,则保存 15 (0000 11111)
位 值 说明
--------------------------------------
00000001 1 支持IM
00000010 2 支持系统消息
00000011 3 支持IM、系统消息
00000100 4 支持邮箱
00000101 5 支持邮箱、IM
00000110 6 支持邮箱、系统消息
00000111 7 支持邮箱、IM、系统消息
00001000 8 支持短信
...
00001111 15 支持邮箱、IM、系统消息、短信紧接着,我们通过封装常用方法来实现增删改,代码如下:
/**
* 判断
* @param mod 用户当前值
* @param value 需要判断值
* @return 是否存在
*/
public static boolean hasMark(long mod, long value) {
return (mod & value) == value;
}
/**
* 增加
* @param mod 已有值
* @param value 需要添加值
* @return 新的状态值
*/
public static long addMark(long mod, long value) {
if (hasMark(mod, value)) {
return mod;
}
return (mod | value);
}
/**
* 删除
* @param mod 已有值
* @param value 需要删除值
* @return 新值
*/
public static long removeMark(long mod, long value) {
if (!hasMark(mod, value)) {
return mod;
}
return mod ^ value;
}总结一下,我们在数据库设计时,将多个标识字段合并成一个字段,并把这个字段改成字符串型方式保存,不仅消除相同字段的冗余,而且当增加新的渠道类别时,不需增加新的字段,但是字符串类型的字段在查询效率和存储空间上不如整型字段。因此,我们可以参考用“位”来解决这个问题。我们采取不同的位来分别表示不同类别的标识字段。

